Leaving Community
Are you sure you want to leave this community? Leaving the community will revoke any permissions you have been granted in this community.
Grand Challenge 3
Grand Challenge 3
Updates
2017-10-09: A new Stage 1b docking component, closing October 23, has been added. Go here for details.
Overview
Grand Challenge 3 (GC3) is a blinded prediction challenge for the computational chemistry community, with components addressing pose-prediction, affinity ranking, and free energy calculations. GC3 is based on six different protein targets, Cathepsin S and five different kinases, and is separated into five subchallenges, some of which involve multiple protein targets. Only Cathepsin S is associated with cocrystal structures, so the kinase components of this challenge focus on affinity ranking and/or free energy predictions. Three of the datasets, Cathepsin S, JAK2 and TIE2, include a free energy prediction component.
The Cathepsin S data were generously provided by Janssen Pharmaceuticals. The kinase datasets were designed by D3R based on single-concentration inhibition data kindly provided by the Structural Genomics Consortium group at the University of North Carolina at Chapel Hill (SGC-UNC). The Kd measurements were then commissioned by D3R and carried out by DiscoverX. All data were reviewed and curated by D3R. Further information on each subchallenge is provided below, and the left-hand menu provides links to the data packages for each subchallenge.
Note that you are free to use the scientific literature and any public-domain protein structures to help with your predictions. Also, if you make multiple submissions, you will now be able to select different anonymity options for different submissions, rather than having to make one choice for all of your submissions; this option will be presented at the time of submission.
Given the size of Grand Challenge 3, we ask participants to please complete the subchallenges in the order they are listed in below, so that all methods can be compared across at least a subset of the challenges (e.g., if you only complete one subchallenge, please complete Cathepsin S).
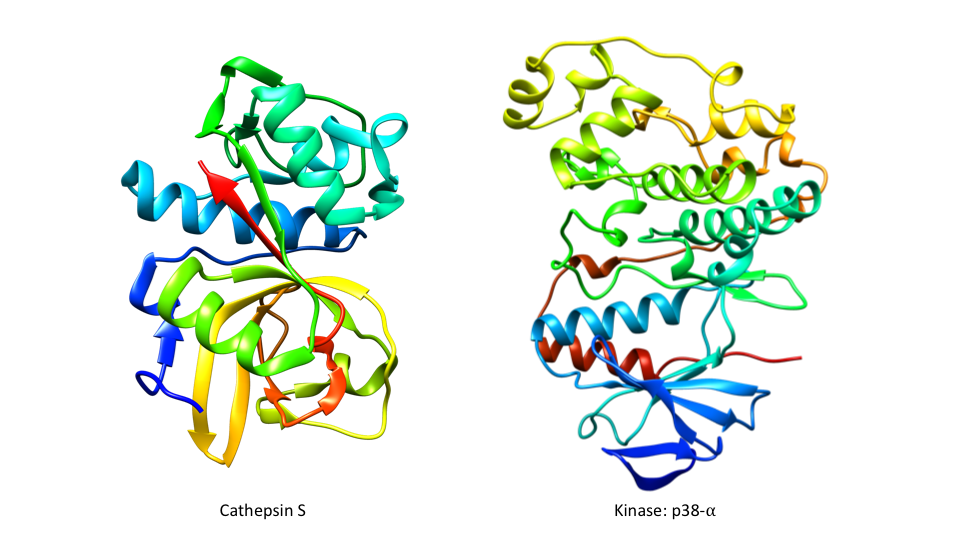
Representative crystal structures of Cathepsin S (PDB 2HHN) and kinase p38-? (PDB 1BL7).
Subchallenges
Subchallenge 1: Cathepsin S
This is a pose-prediction, affinity ranking/scoring, and free energy challenge, occurring in two stages. It is based on a dataset comprising 26 ligand-protein co-crystal structures with resolution <3.0 Å, and binding data (IC50s) spanning three orders of magnitude for 136 compounds. This dataset is part of a larger IC50 dataset with hundreds more compounds, which will be used for future D3R challenges, so that participants may build on what they learn through successive studies of this target.
Note that the cocrystal structure with ligand CatS_14 has a dimethylsulfoxide (DMSO) molecule in a critical bridging location; and six other cocrystal structures with seven other ligands, CatS_2, CatS_17, CatS_20, CatS_22, CatS_23, and CatS_24, have a sulfate (SO4) ion in a critical bridging location. In order to facilitate the docking of these ligands, representative structures of Cathepsin S, with the key SO4 and DMSO, but no ligands, are provided in the dataset, and participants are invited to use this information in their docking calculations. In addition, we ask participants to use the provided SO4-bound structure as the reference structure for superposition of all pose predictions, in order to facilitate evaluation. Note, however, that no key sulfate or DMSO molecules were present in the other cocrystal structures.
- Challenge:
Stage 1: predict the crystallographic poses of 24 ligands. Predict affinities, or affinity rankings, for 136 ligands and/or the absolute or relative binding affinities for the designated free energy subset of 33 compounds.
Stage 1b: predict the crystallographic poses of the 24 ligands in a self docking challenge with the corresponding receptor structures. No affinity calculations in this stage.
Stage 2: predict affinities, or affinity rankings, for all 136 ligands and/or the absolute or relative binding affinities for the free energy subset of 33 compounds, this time taking advantage of the poses of the 24 compounds for which cocrystal structures are available.
- Inputs:
Stage 1: SMILES strings of the 24 ligands to be docked and the FASTA sequence of the target, Cathepsin S. Two crystal structures, one of a SO4-bound and the other of a DMSO-bound Cathepsin S. SMILES strings of the 136 compounds for affinity prediction or ranking. SMILES strings of the ligand subset (33 compounds) for the calculation of relative or absolute binding affinities; these compounds were chosen to be similar enough to allow alchemical calculation of relative binding free energies.
Stage 1b: SMILES strings of the 24 ligands to be docked, and the receptor structures cocrystallized with each ligand.
Stage 2: the same inputs as for Stage 1, supplemented by the 24 co-crystal structures.
- Outputs:
In Stage 1, your predicted poses for the 24 ligands, in a coordinate system aligned with the S04-bound Cathepsin S structure provided in the inputs. Your predicted affinities, or affinity rankings, for all 136 compounds and/or your predicted absolute or relative binding affinities (in kcal/mol) for the free energy subset of 33 compounds.
In Stage 1b, predicted crystallographic poses of the 24 ligands in the coordinate systems of the receptor structures provided. When Stage 1 closes, we will release the crystallographic poses of the 24 ligands.
In Stage 2, your predictions of the affinity rankings of all 136 compounds and/or absolute or relative binding affinities (in kcal/mol) for the free energy subset of 33 compounds.
- Dataset name: Cathepsin S
- Subchallenge timeline:
- Stage 1:
- September 1 - October 3
- Stage 1b:
- October 9 - October 23 23:59 PST
- Crystallographic structures released
- Stage 2:
- October 25 - December 15
Subchallenge 2: Kinase Selectivity
This subchallenge tests the ability of current methods not only to rank ligands by affinity for a given target, but also to predict selectivity of ligands across targets. It is based on three datasets with dissociation constants (Kd) for 85, 89, and 72 diverse ligands, for kinases VEGFGR2, JAK2 and p38-?, respectively. Initially, this challenge started with a larger set of measurements for 100 ligands that were all common across all three kinases, but some of the data had to be removed because it was unblinded by a recent publication [1]. Thus, of the remaining ligands, 54 are common across the three kinase datasets. Because there are no new cocrystal structures, there is no pose-prediction component, and this challenge has only one stage. Note that the phosphorylation states of these kinases is not specified.
- Challenge:
Predict affinities, or affinity rankings, for all ligands.
- Inputs:
FASTA sequence of each of the three targets: VEGFR2, JAK2, and p38-?. SMILES strings of the 85, 89, and 72 compounds for affinity prediction or ranking with each of three targets, VEGFR2, JAK2, and p38-?, respectively.
- Outputs:
Your predicted affinity rankings, for all 85, 89, and 72 compounds.
- Dataset names: VEGFR2, JAK2_SC2, and p38-?
- Subchallenge timeline: September 1 - December 1
Subchallenge 3: Kinase Activity Cliff JAK2_SC3
This is an affinity ranking/scoring, and free energy challenge, designed to test the ability of current methods to detect large changes in affinity due to small changes in chemical structure. The dataset comprises 17 congeneric compounds with Kd values for the kinase JAK2. Note that the chiral compounds were measured as racemates. Although this makes for a more complex challenge, it models a situation that is not uncommon in pharmaceutical drug discovery. Similar to Subchallenge 2, this challenge has no pose-prediction component and therefore, only one stage. Note that the phosphorylation state of this kinase is not specified.
- Challenge:
Predict affinities, or affinity rankings, and optionally the absolute or relative binding affinities for 17 ligands.
- Inputs:
FASTA sequence of the target JAK2. SMILES strings of the 17 compounds.
- Outputs:
Your predicted affinity rankings, and/or your predicted absolute or relative binding affinities (in kcal/mol) for all 17 compounds.
- Dataset name: JAK2_SC3
- Subchallenge timeline: September 1 - December 1
Subchallenge 4: Kinase Activity Cliff TIE2
This is also an affinity ranking/scoring, and free energy challenge, designed to test the ability of current methods to detect large changes in affinity due to small changes in chemical structure. The dataset comprises 18 congeneric ligands with Kd values for the kinase TIE2. From this full set of 18, two free energy subsets of 4 and 6 compounds were selected as amenable to alchemical relative binding free energy calculations. Similar to Subchallenge 2, this challenge has no pose-prediction component and therefore, only one stage. Note that the phosphorylation state of this kinase is not specified.
- Challenge:
Predict affinities, or affinity rankings, for 18 ligands and/or predict the absolute or relative binding affinities for two designated free energy subsets of 4 and 6 compounds.
- Inputs:
FASTA sequence of the target TIE2. SMILES strings of the 18 compounds for affinity prediction or ranking. SMILES strings of the free energy subsets of 4 and 6 compounds for the calculation of binding free energies.
- Outputs:
Your predicted affinity rankings, for all 18 compounds and/or your predicted relative binding affinities (in kcal/mol) for the free energy subsets of 4 and 6 compounds.
- Dataset name: TIE2
- Subchallenge timeline: September 1 - December 1
Subchallenge 5: Kinase Mutants
This subchallenge tests the ability of computational methods to predict the effect of target mutations on small molecule binding affinities. The dataset consists of Kd values for two compounds versus the wild type and five mutants of the nonphosphorylated ABL1 protein, ABL1(F317I), ABL1(F317L), ABL1(H396P), ABL1(Q252H), and ABL1(T315I). Similar to Subchallenge 2, this challenge has no pose-prediction component and therefore, only one stage.
- Challenge:
Predict affinities, or affinity rankings, for all mutants for each of the two ligands.
- Inputs:
FASTA sequence of each of the ABL1 targets: nonphosphorylated ABL1 wild type protein and mutants: ABL1(F317I), ABL1(F317L), ABL1(H396P), ABL1(Q252H), and ABL1(T315I). SMILES strings of the 2 compounds for affinity prediction or ranking with each of the targets.
- Outputs:
Your predicted affinities, or affinity rankings, for the six targets with both compounds.
- Dataset name: ABL1
- Subchallenge timeline: September 1 - December 1
References:
1. Drewry DH, Wells CI, Andrews DM, et al (2017) Progress towards a public chemogenomic set for protein kinases and a call for contributions. PLOS ONE 12:e0181585. doi: 10.1371/journal.pone.0181585
Search
D3R Grand Challenge Tags
About
Welcome to the Drug Design Data Resource Community. D3R is funded in part by NIH grant 1U01GM111528 from the National Institute of General Medical Sciences